Experimental Design and Blocking
Before we start analyzing data in Python, it’s important to understand how to design experiments and how to collect data. Experiments are done to see if a treatment has an effect on the outcome, also known as the response. Experiments aim to answer the question: Does something work? In other words, does a specific treatment cause a specific response?
In experiments, the researcher decides who gets the treatment and who does not. The group of subjects who get the treatment are called the treatment group and the group of subjects who do not get the treatment are called the control group. The researchers collect data on the control group to make comparisons between outcomes with the treatment and outcomes without the treatment. If the researcher plays no role in deciding who gets the treatment and who does not, the investigation is called an observational study. For now, we are going to focus on experiments:
The Ideal Experimental Design
When designing experiments, the goal is to make the treatment group and control group as alike as possible. There are many ways to divide the subjects into two groups, however, randomization is best!
Randomly dividing the subjects into the 2 groups is the most likely to make the treatment and control groups as alike as possible because it eliminates human bias. With enough subjects, differences average out. Not only differences that the researcher has identified as relevant, but on all characteristics, including the hidden ones that the researcher might not realize are important.
The ideal experimental design is the randomized controlled double-blind experiment.
Randomized controlled double-blind experiments are the gold standard in the medical field. They are also becoming more commonly used in other fields such as economics. A randomized controlled double-blind experiment must meet three criteria:
Randomization: The treatment and control groups are randomly assigned. Random assignment to treatment and control works best to make the treatment and control groups as alike as possible because it eliminates systematic differences (bias). With enough subjects, random differences average out.
Controlled: There is an explicit comparison group (control group). An explicit control group allows you to more accurately measure the impact of the treatment on the outcome. Without one, you may see more positive results than what really exists.
Double-Blind: Neither the subjects nor those who are evaluating them know who is in the treatment and control group. Whether people think they have received the treatment can affect their response. To separate the effects of the actual treatment from the idea of treatment, the subjects shouldn’t know which group they are in. In other words, they should be “blind” to this knowledge. Knowing which subjects received the treatment and which did not can bias the people evaluating the results. To eliminate this bias, evaluators should be “blind” to this knowledge.
How to make an experiment double-blind.
Placebo: We can give the control group a fake treatment called a placebo. With a placebo, the subjects won’t know what group they are in so differences in the subjects’ responses can be attributed to the treatment itself and not the idea of treatment.
3rd Party Evaluators: We can have a 3rd party evaluator who collects data and makes sure it is anonymous. This makes it so that the researchers do not know who is in which group. This eliminates the problem of researchers treating subjects differently depending on which group they are in.
Why is the randomized controlled double-blind experiment ideal?
If an experiment is designed correctly (randomized, controlled, and double-blind), at the end of the study, any differences in the treatment and control groups can be attributed to the treatment itself. We can trust these studies and more importantly, we can conclude that the treatment did cause the response. This is incredibly powerful!
Blocking for Small Samples
With enough subjects, random differences average out when we randomly divide subjects into a treatment and control group. But what do you do if you have a small sample?
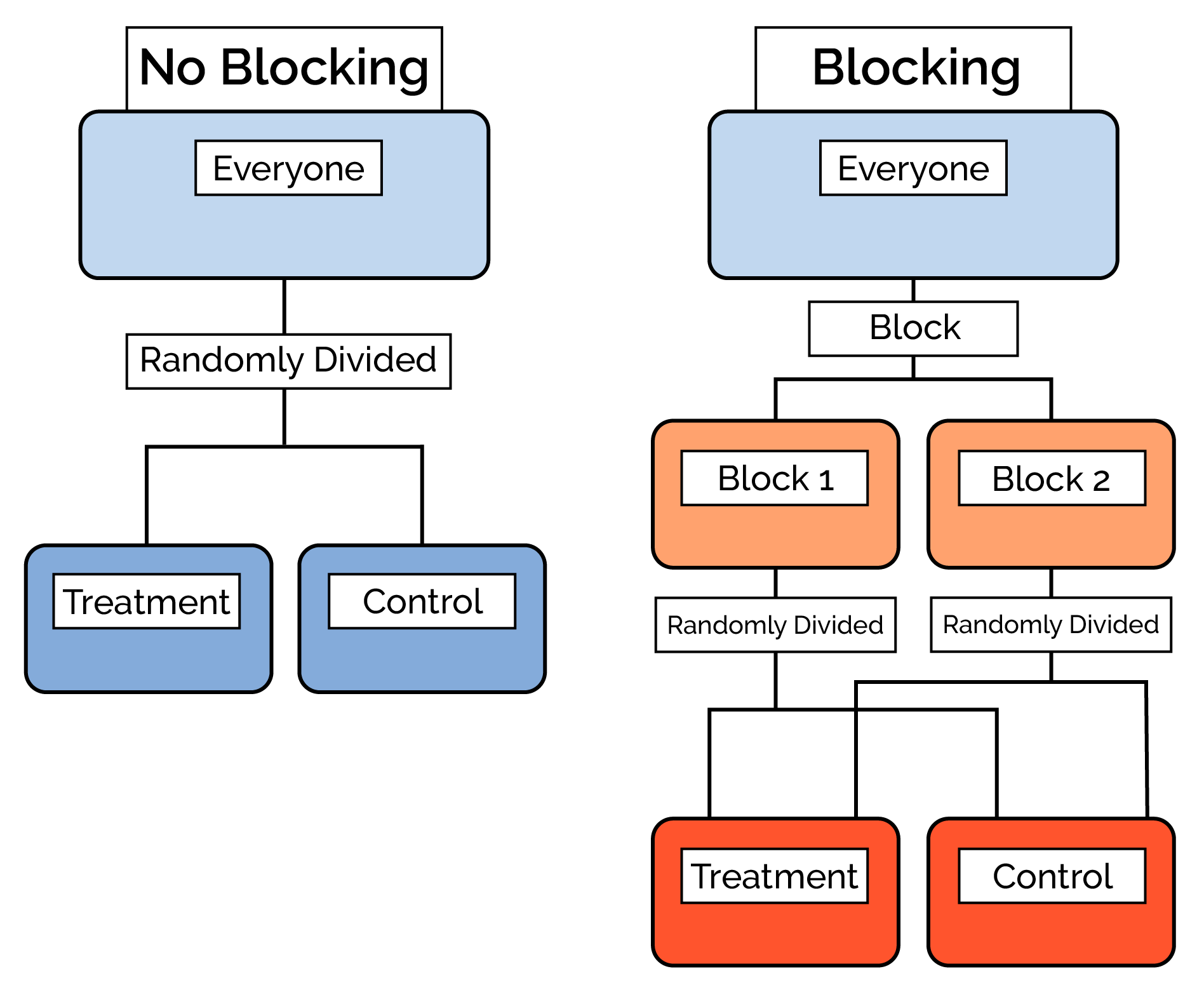
Blocking
With small samples, it's possible to randomly divide the subjects and still get different groups. In order to address this, researchers “block” subjects into relatively homogeneous groups first and then randomly decide within each block who becomes a part of the control group and who becomes a part of the treatment group.
Blocking first, then randomizing ensures that the treatment and control group are balanced with regard to the variables blocked on. If you think a variable could influence the response, you should block on that variable.