Combining DataFrames by Joining
pandas has a feature called join that allows you to join in columns from one or more other DataFrames by either their index or on a "key" column that you specify.
Say we have two DataFrames with contents as follows:
df1 = pd.DataFrame([
{'Name': 'Saul', 'Favorite Color': 'Maroon', 'Show': 'BCS'},
{'Name': 'Walter', 'Favorite Color': 'Blue', 'Show': 'BB'},
{'Name': 'Kim', 'Favorite Color': 'Red', 'Show': 'BCS'},
{'Name': 'Howard', 'Favorite Color': 'Green', 'Show': 'BCS'}
])
df2 = pd.DataFrame([
{'Name': 'Kim', 'Favorite Color': 'Red', 'Show': 'BCS'},
{'Name': 'Walter', 'Favorite Color': 'Blue', 'Show': 'BB'},
{'Name': 'Jesse', 'Favorite Color': 'Maroon', 'Show': 'BB'},
{'Name': 'Saul', 'Favorite Color': 'Maroon', 'Show': 'BCS'}
])Our data between the two columns overlap, so we might be inclined to combine the two DataFrames. The join function in pandas allows us to do this and specify how exactly we want this join to occur.
Using Join
The simplest operation is too preform a standard join (which is a left join), which will simply tack on the values of the second DataFrame to the right of the first one. By default this will join on matching indexes.
| Name(right) | Favorite Color(right) | Show(right) | Name | Favorite Color | Show | |
|---|---|---|---|---|---|---|
| 0 | Saul | Maroon | BCS | Saul | Maroon | BCS |
| 1 | Walter | Blue | BB | Walter | Blue | BB |
| 2 | Kim | Red | BCS | Kim | Red | BCS |
| 3 | Howard | Green | BCS | Jesse | Maroon | BB |
Here we also specify a rsuffix since our DataFrames have matching column names. This makes sure that all of our columns have unique names by adding a suffix to the right DataFrame. (you can also specify a lsuffix to append to column names on the left side)
Sometimes, you might want to join on something different that just the index, so we can also specify a "key" column to join on like this (we'll also specify both a left and a right suffix for we can tell where data is coming from):
| Name | Favorite Color(left) | Show(left) | Favorite Color(right) | Show(right) | |
|---|---|---|---|---|---|
| 0 | Saul | Maroon | BCS | Maroon | BCS |
| 1 | Walter | Blue | BB | Blue | BB |
| 2 | Kim | Red | BCS | Red | BCS |
| 3 | Howard | Green | BCS | NaN | NaN |
⬆ We'll need to set the index of the right DataFrame to the Name column to allow for the matching to occur.
Note: You'll also see that is data that doesn't exist prior to the join is populated with NaN, which is something you may have to deal with in order to use your DataFrame properly
Types of Joins
You might notice that in the after the previous join command, we have rows with "Kim", "Saul", and "Walter", who appear is both DataFrames, and a row with "Howard" who appears in the left DataFrame. However "Jesse", who only appears in the right DataFrame is dropped. This is because by default the join command in pandas will perform a left join (i.e. keep every value in the left and the intersection).
There are 4 types of joins, which can be visualized using a venn diagram:
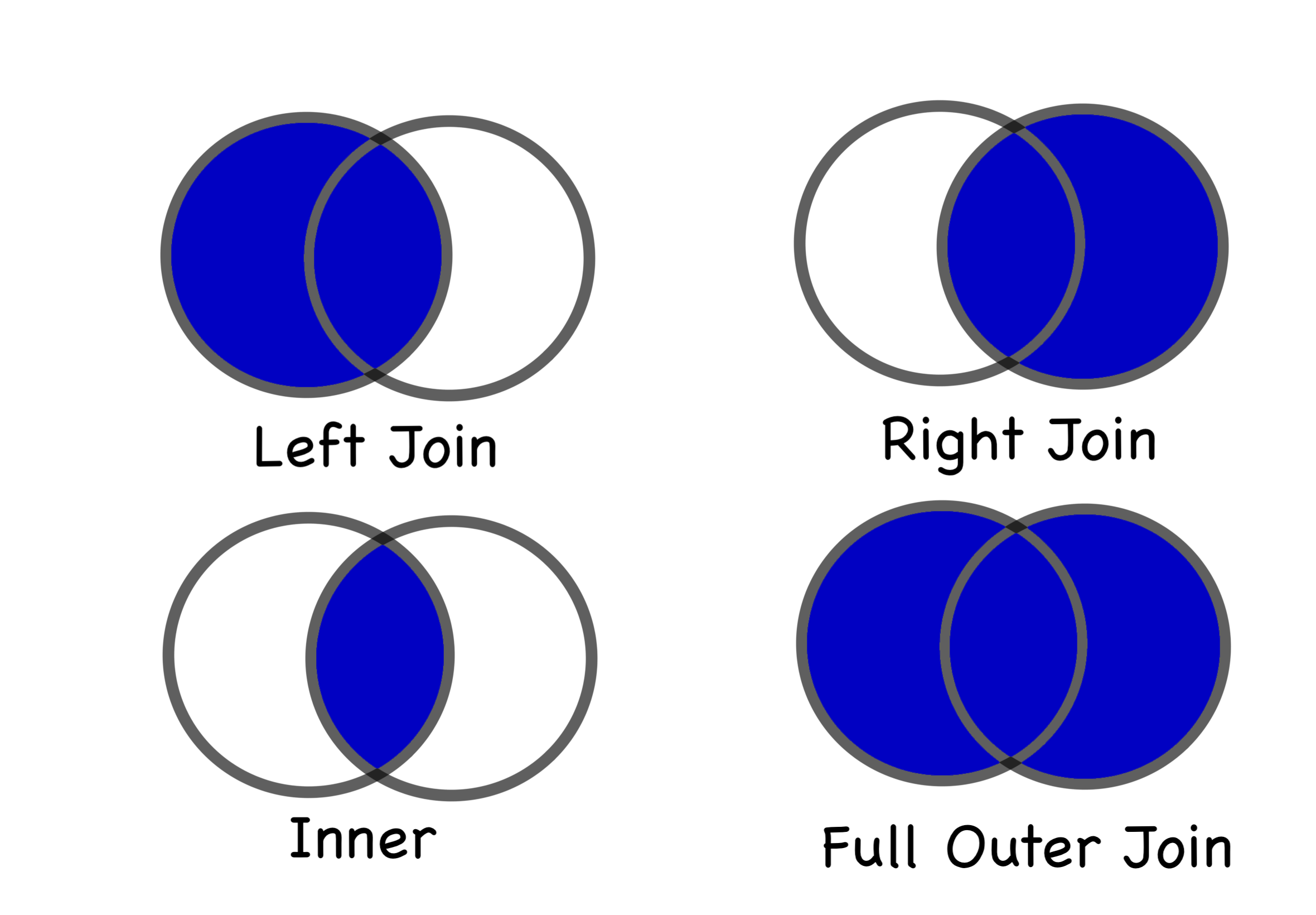
So if we wanted a join that kept every value in the right DataFrame and discarded any value not in the right DataFrame (including its intersection with the left DataFrame) we can specify a right join like this:
| Name | Favorite Color(left) | Show(left) | Favorite Color(right) | Show(right) | |
|---|---|---|---|---|---|
| 0.0 | Saul | Maroon | BCS | Maroon | BCS |
| 1.0 | Walter | Blue | BB | Blue | BB |
| 2.0 | Kim | Red | BCS | Red | BCS |
| NaN | Jesse | NaN | NaN | Maroon | BB |
The inner join will only join on the overlap between the two DataFrames:
| Name | Favorite Color(left) | Show(left) | Favorite Color(right) | Show(right) | |
|---|---|---|---|---|---|
| 0 | Saul | Maroon | BCS | Maroon | BCS |
| 1 | Walter | Blue | BB | Blue | BB |
| 2 | Kim | Red | BCS | Red | BCS |
The outer join will include all data in both:
| Name | Favorite Color(left) | Show(left) | Favorite Color(right) | Show(right) | |
|---|---|---|---|---|---|
| 0.0 | Saul | Maroon | BCS | Maroon | BCS |
| 1.0 | Walter | Blue | BB | Blue | BB |
| 2.0 | Kim | Red | BCS | Red | BCS |
| 3.0 | Howard | Green | BCS | NaN | NaN |
| NaN | Jesse | NaN | NaN | Maroon | BB |
Another useful property of join is that if there are multiple matches in a key column, it will return the combinations:
| Name(left) | Favorite Color(left) | Show | Name(right) | Favorite Color(right) | |
|---|---|---|---|---|---|
| 0 | Saul | Maroon | BCS | Saul | Maroon |
| 0 | Saul | Maroon | BCS | Kim | Red |
| 2 | Kim | Red | BCS | Saul | Maroon |
| 2 | Kim | Red | BCS | Kim | Red |
| 3 | Howard | Green | BCS | Saul | Maroon |
| 3 | Howard | Green | BCS | Kim | Red |
| 1 | Walter | Blue | BB | Walter | Blue |
| 1 | Walter | Blue | BB | Jesse | Maroon |
Here we'll get rows of every combination of matching show with the other DataFrame.
You can read more about join in the pandas documentation here: pandas documentation.